
Lean Data Vault: A Pragmatic Approach to Data Modeling in the Lakehouse
Introduction
Data Vault is a proven methodology for building scalable, auditable data platforms. I consider myself a fundamental advocate of Data Vault – its concepts of hubs, satellites, and links provide a solid foundation for traceability and parallelization.
However, in real-world projects, I often experienced that the full methodology was too heavy for organizations to adopt consistently. Out of this need, I developed a Lean Data Vault approach: rooted in the principles of Data Vault, but simplified to focus on what truly matters – data quality, flexibility, and speed of delivery.
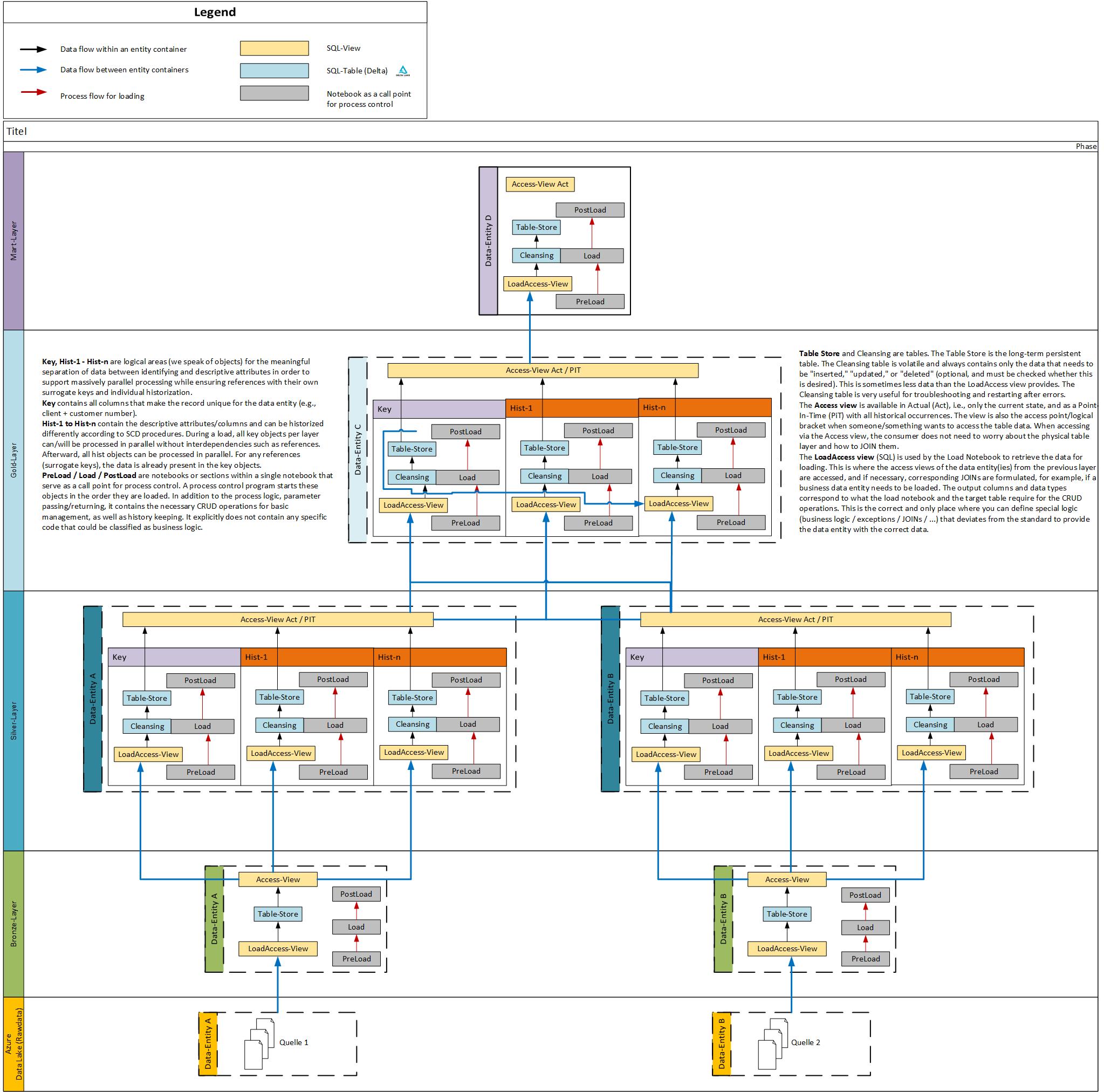
Core Principles of Lean Data Vault
1. Key Tables (like Hubs)
- Contain only the attributes that uniquely define a record (e.g., tenant + customer number).
- Generate surrogate keys as technical identifiers for unambiguous referencing.
- Optionally use hash keys for faster lookups and early-arriving fact handling.
2. Hist Tables (like Satellites)
- Hold descriptive attributes and enable historization.
- Usually one per entity, but additional Hist tables can be created for fast-changing attributes.
3. Surrogate-Driven Referential Integrity
- References are always built on surrogate keys.
- Broken links can be reported and monitored for data quality.
- Early-arriving facts are handled via inferred members, ensuring surrogate keys exist even before the master record arrives.
Data Quality as a First-Class Citizen
A central motivation behind Lean Data Vault is data quality. In my experience, too many modern implementations sacrifice transparency for speed, skipping essential checks and controls. I take the opposite stance: traceability and control mechanisms must be built into the model itself.
Here’s how Lean Data Vault enforces data quality:
- Surrogate Keys as Technical Anchors
- Every record in a Key table is assigned a surrogate key (integer-based, auto-incremented).
- This guarantees technical uniqueness even when source business keys are composite, duplicated, or unstable.
- Business Keys for Domain Uniqueness
- Business keys remain the semantic identifiers (e.g., customer number, order ID).
- They ensure functional uniqueness, but surrogate keys are used for all technical relationships.
- Referential Integrity via Surrogate Keys
- All references (e.g., orders → customers) are based on surrogate keys.
- Missing references are immediately visible and can be monitored as data quality issues.
- Handling Missing References (Early-Arriving Facts)
- Dummy Record: Missing references point to a default surrogate key (e.g.,
1). - Inferred Member: Insert placeholder entries marked as inferred, later enriched when the master data arrives.
- Dummy Record: Missing references point to a default surrogate key (e.g.,
With these mechanisms, Lean Data Vault enables data quality monitoring by design – broken references are never hidden but reported transparently.
Separation of Concerns in Code Artifacts
Lean Data Vault is not only about table design – it’s also about a clear separation of code artifacts. Borrowed from software engineering, the principle of Separation of Concerns (SoC) makes systems easier to maintain, extend, and automate.
- Tables (Key & Hist)
Designed solely for CRUD operations and historization. - LoadAccess Views
- The outer SELECT defines the structure and data types of the target table.
- The inner SELECT assembles the actual data – either simple copy logic (Bronze → Silver) or business-specific transformations.
This strict separation brings two key benefits:
- Metadata-Driven Code Generation with Analytixus
- Because the structures of Keys and Hists are predictable, all CRUD-related code can be generated automatically, even up to the Gold layer.
- Developers don’t waste time on boilerplate – they focus on value.
- Flexibility for Business Logic
- Business rules are isolated in the inner SELECT of the LoadAccess View.
- Engineers only adjust this part when business logic changes.
- All other artifacts remain untouched and stable.
Why Lean Data Vault Matters
Traditional 3NF or other modeling approaches often result in deep dependency chains that slow down processing. Full Data Vault solves this problem through parallelism, but results in high overhead and rigidity.
Lean Data Vault offers a balanced alternative:
- Agility: Only two table types (Keys & Hists).
- Automation: CRUD code generation directly from metadata.
- Sustainability: Business logic isolated in views, not scattered across artifacts.
- Transparency: Surrogate-driven referential integrity makes data quality issues measurable.
Conclusion
Lean Data Vault is not a replacement for Data Vault – it is a pragmatic adaptation. It embraces the strengths of Data Vault while simplifying the approach to meet the realities of fast-paced, metadata-driven lakehouse projects.
With this methodology, we can deliver trusted, auditable, and maintainable data pipelines – while giving engineers the freedom to focus their expertise where it matters most: business logic, not boilerplate code.
Lean Data Vault: A Pragmatic Approach to Data Modeling in the Lakehouse - Analytixus - The Analytics-DRUID
[…] Ping back: https://andyloewen.de/2025/09/17/lean-data-vault-a-pragmatic-approach-to-data-modeling-in-the-lakeho… […]