The Real Problem with AI Agents Isn’t Hallucination. It’s Amnesia.
I’ve been building data systems for years. More recently, I’ve been building AI agent systems. And the biggest problem I keep running into isn’t the one most people talk about.
It’s not hallucination. It’s not missing domain knowledge. It’s not weak reasoning.
The biggest problem is: AI agents forget everything.
A concrete example
I work with my own metadata framework called Analytixus. Instead of writing code directly, I define data models in DnAML declaratively – structures, relationships, rules – and generate code from them deterministically. That’s intentional: traceability, repeatability, control. The AI describes what should be built. A deterministic generator turns that into code.
I gave an AI agent my metadata format and asked it to define relationships between tables by analyzing an existing data model in DnAML. Technically, it did well. But it didn’t follow my naming conventions. The rule is simple: only role-based references get an explicit name (e.g. BillToCustomerID, LastEditedBy). Standard references stay unnamed, because my code templates expect that and synthesize the actual name themselves. The agent named everything anyway.
I corrected it. Next attempt, new session, same task: same mistake. The correction was gone. The session was over.
The frustrating part: the convention already existed in my central experience store – Ogham, a system I’m building in parallel. Another agent had stored it there as episodes and an insight. But the agent that got the task never queried Ogham. Not because it couldn’t. Because it didn’t think to.
Why Ogham?
Analytixus is my analytics druid – a metadata interpreter that describes analytics solutions and generates code. But a druid without memory is worthless. In Celtic tradition, Ogham was the script druids used to carve their knowledge permanently into stone – passed down across generations.
Ogham is the memory Analytixus needs. Without it, every project starts from zero. With it, every insight becomes persistent, every decision traceable, every pattern findable. A druid without memory is just a consultant without experience. A druid with memory is a system that learns.
Three things that get confused constantly
When I talk to developers and architects about this problem, I notice three concepts get mixed up regularly. No judgment – I didn’t separate them cleanly for a long time either.
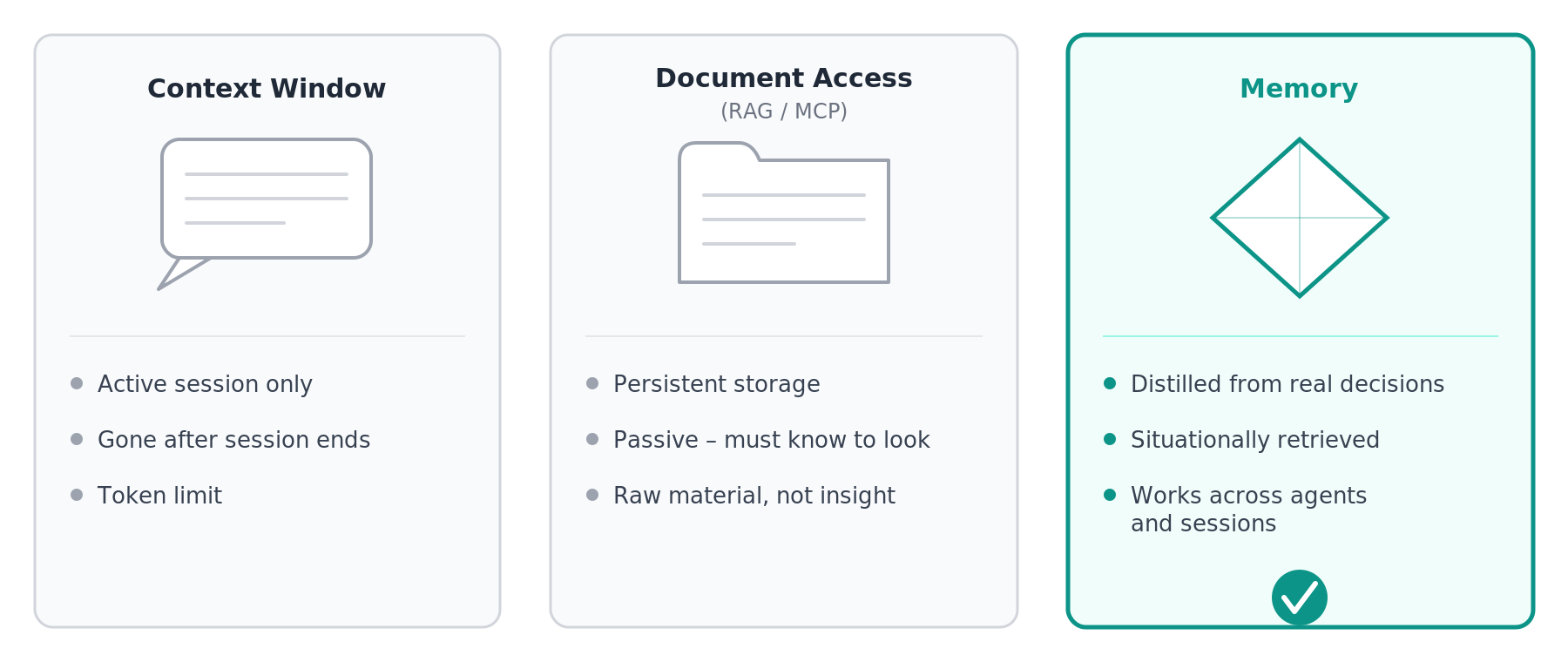
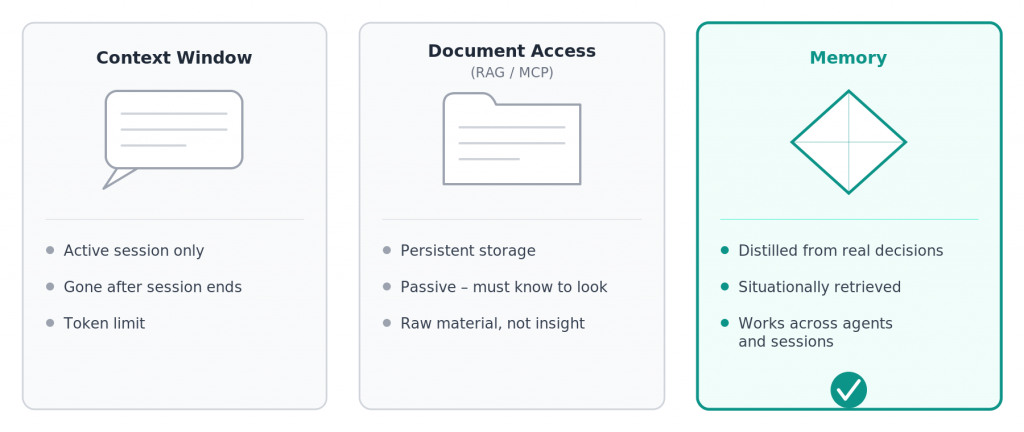
Context window is what’s currently in the chat. Everything you’ve told the agent in this session, every correction, every decision. Ephemeral. Gone after the session. And limited – with complex tasks involving many documents and long conversations, you hit the ceiling fast.
Document access (RAG, MCP, file attachments) is what the model can look up. You give it access to files, databases, external sources. That’s significantly better than the context window alone. But it has a critical weakness: these are sources, not distilled experience. The agent gets raw material – it has to decide what’s relevant, and it has to know to look in the first place.
Memory is something different. It’s what has been distilled from past decisions into reusable patterns. Not the raw data – the insight. Retrievable by situation. Across chats and agents. And – this is the key point – actively injected before the agent starts the task.
Most systems I see have context windows and document access. Actual memory, in this sense, is rare.
Why the common workarounds don’t hold up
Bloating the system prompt. The classic approach: write all conventions, rules, and decisions into the system prompt or skill definition. Works up to a point. Doesn’t scale. At 50 conventions, the prompt is longer than the task. Every new insight has to be manually maintained. And tokens cost money and latency.
Providing files. Better than nothing. But a file isn’t memory. It contains information, not distilled decisions. The agent still has to know it should look – and what to look for. And it has to extract the relevant piece from a potentially long document on its own.
Chat history. Helps within a session. The next session starts from zero. And another agent – in a different chat, with a different task – has no access to the first agent’s history.
Provider memory. Microsoft, OpenAI, Anthropic – all working on memory features. That’s good and important. But most approaches are chat-bound or user-bound. An agent remembers its chat with you. Not the correction another agent made in a different context. Not the decision made three weeks ago in a different project.
The real problem: scaling across agents
Single agents with good memory are a solved problem – or will be soon. The real problem is different.
You don’t solve a complex IT transformation with a single agent and a single chat. You need specialized agents for analysis, architecture, development, testing, compliance. These agents work in parallel, sequentially, across different contexts. And they all need access to the same accumulated experience.
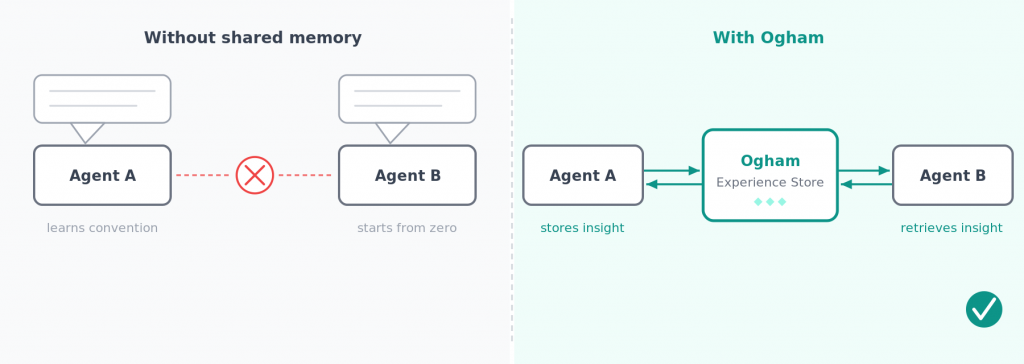
If Agent A learns a convention and Agent B does the same task three days later, Agent B shouldn’t start from zero. If a project makes a decision, the next project should benefit from it. If a correction is made, it shouldn’t only apply in that one chat.
That requires a central memory – one that works across agents, chats, tasks, and projects.
What I built from this
Ogham is my approach to exactly this problem. It’s an experience store for AI agent systems.
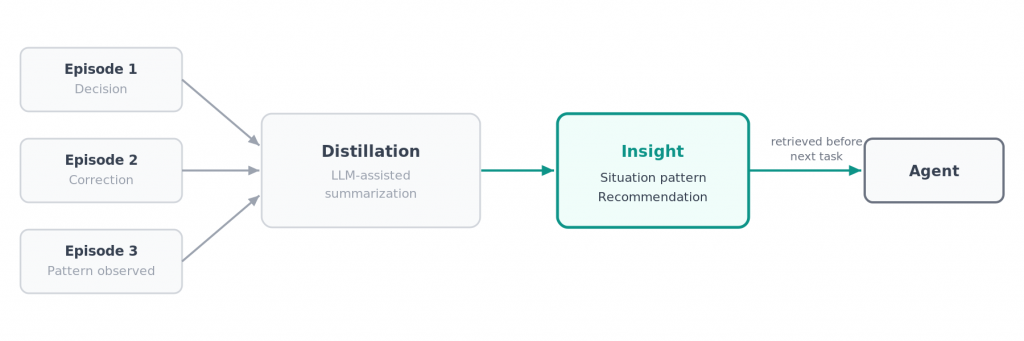
The principle: every relevant decision, every correction, every learned pattern is stored as an episode. From multiple similar episodes, the system distills insights – reusable findings with a situation description and a concrete recommendation. Before each task, the agent queries Ogham: are there experiences relevant to this situation? The answer flows into the context – not as raw data, but as distilled knowledge.
That sounds simple. The complexity is in the details.
Search has to work – the best memory is useless if the agent can’t find the relevant experience. Ogham combines semantic search with lexical search, because both approaches have weaknesses on their own: semantic search finds similar concepts but loses specific terms. Lexical search finds exact matches but fails on synonyms.
The agent has to actually use the memory. An agent won’t consistently query its memory first unless you force it to. In my system, the Ogham query isn’t an optional step – it’s an enforced reflex before the actual task begins.
And distillation has to preserve the right information. More abstraction often means worse memory – if specific terms disappear during compression, search finds nothing later.
Why not a knowledge graph?
A natural next question: why not use a knowledge graph with weighted edges? Relationships between insights, explicit connections, graph traversal at query time.
I’ve thought about it. My current answer is: not yet, and maybe not for a while.
The core problem is that edge weights would need to be determined situationally at query time – not stored statically, but computed dynamically based on the current context. That’s technically possible, but it adds significant complexity. You either need an embedding model computing similarities between nodes and the query at runtime, or you maintain weights manually – which collapses quickly as the graph grows.
There’s a more fundamental issue: a graph makes relationships between insights explicit. But if keeping the insights themselves clean is already hard, a graph adds another maintenance dimension. Not just “is this insight still valid?” but also “is this edge still valid? With what weight?”
My view: a graph becomes valuable when you have so many insights that the relationships between them are themselves informative. That’s not the problem I have today. Ogham’s current architecture – episodes, distilled insights, hybrid search – solves the actual bottleneck without the overhead. I’ll revisit when the data justifies it.
Why this matters
I think we’re at a point where most AI agent systems are good enough for simple, isolated tasks. For complex, long-running, multi-agent workflows, one critical piece is still missing: institutional memory.
Not the memory of a single chat. Not a knowledge base someone maintains manually. But a system that learns from operation – from real decisions, real corrections, real project experience – and makes that knowledge available situationally and automatically.
That’s the problem I’m working on. Ogham is my first approach – not the final answer.
I write regularly about AI agent systems, metadata-driven development, and the reality behind the buzzwords. If this is relevant to you, follow me on LinkedIn.