Discipline does not emerge by convincing the agent
Discipline does not emerge by convincing the agent – it emerges by removing the choice
In my last article, I wrote about the memory problem in AI agents. Why they forget. Why that is not a bug, but architecture. And why a central experience store is the right direction.
The most common reaction to that was simple:
“Then just give the agent access to the store.”
Sounds reasonable. I did that. It did not solve the problem.
Not because the store was empty. Not because retrieval was broken. Not because the query API failed. But because the agent simply did not look.
That is the real point. Access is not discipline. A tool is not a reflex. And a prompt is not enforcement.
The problem is not access. The problem is the missing reflex.
I had a system that looked complete on paper. The agent had access to a knowledge store. The store contained the right experience. The query function worked.
But the agent did not call it reliably. Sometimes it did. Sometimes it did not. Depending on the task wording. Depending on the current context window. Depending on whether the model “thought of it” in that turn.
So I tried the obvious fix. I put it into the prompt.
“Before every task, query the knowledge store.”
Clear instruction. Direct wording. Still not reliable.
Sometimes the agent followed it. Sometimes it answered directly because the task looked easy. Sometimes the instruction was pushed too far up in the context window. Sometimes the model simply prioritized producing an answer over doing the lookup first.
That is not a model bug. That is how language models work. Every turn is a fresh decision under competing signals. “Look it up first” competes with “answer now”. And “answer now” usually wins. Because it is shorter. Because it is faster. Because it feels locally sufficient.
Why treating agents like colleagues is the wrong mental model
This is the trap many people fall into when they start building agent systems. They treat agents like colleagues.
“Please remember this.”
“Do not forget to check first.”
“Look it up before you answer.”
That works with humans often enough. A human builds habits. A human remembers that checking first is useful. A human develops a reflex.
An agent does not. It has no habit. It has no cross-turn reflex. It has no durable procedural discipline. Each task starts from scratch. And the decision whether to look something up is made again every single time.
“Please remember” is not a mechanism. It is hope.
The architectural shift: remove the reflex from the agent’s judgment
What actually worked was not a better reminder. It was an architectural change.
Not: “Please check first.”
But: The first check happens before the agent even sees the task.
The harness — the middleware around the agent — queries the knowledge store first. Then the agent receives the task together with a structural signal: there is prior experience relevant to this topic.
That matters. Because the first reflex is no longer optional. The agent cannot skip the existence check if the existence check is not its decision anymore.
This is the core design principle:
The harness owns the reflexes. The agent owns the reasoning.
Everything non-negotiable belongs into the structure. Everything judgment-heavy stays with the agent.
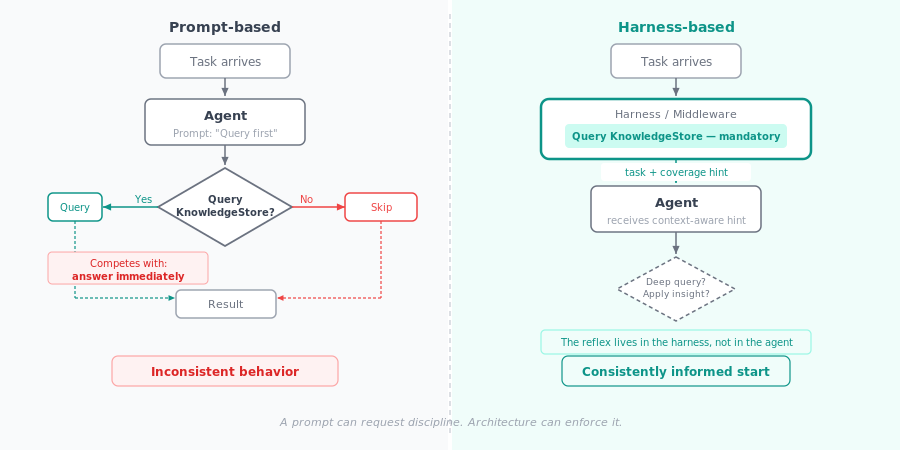
A prompt can request discipline. Architecture can enforce it.
Scout and agent: two roles, two different jobs
In practice, I split this into two steps. That matters because the two steps solve different problems.
The Scout is a cheap and fast pre-check. It runs in the middleware before the agent sees the task. It does not have the full context. It only gets a rough situation description. Its job is not precision — it is reliability. It makes sure that the system checks at all, and it gives the agent an initial signal that relevant experience may exist.
The Agent does the precise deep query. Because the agent has the full task context. It knows the concrete identifiers. It sees the actual constraints. It can formulate a much better retrieval query than the Scout can.
That division of labor is useful. But here is the important correction.
Even if the Scout queried the KnowledgeStore and tells the agent that relevant knowledge exists, that is still not a guarantee that the agent will perform its own deep query.
That is exactly the trap. People see the Scout signal and assume the problem is solved. It is not.
A coverage hint is only a hint. The agent can still ignore it. The agent can still answer from local plausibility. The agent can still skip the deeper retrieval step.
I built the Scout. I was relieved. The harness queried first. The agent got the hint. Three days later, the same agent ignored it. Full context in the task. Coverage signal present. Agent answered from local plausibility anyway. The Scout had run. The hint was there. The agent did not care.
So the Scout pattern helps. But by itself it is still not enough.
If the deep query is critical, then that step also has to be structurally guided. Not merely suggested. Not buried in a prompt. Not left to good intentions.
The Scout solves one problem: that the system checks for prior knowledge at all. It does not automatically solve the second problem: that the agent actually performs the context-rich retrieval needed for a high-quality answer.
That distinction is easy to miss. And it matters.
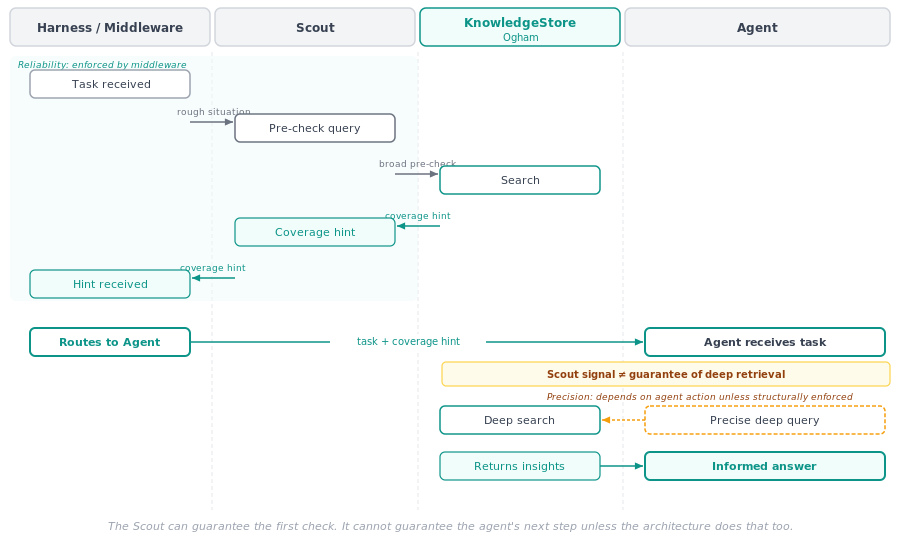
The Scout can guarantee the first check. It cannot guarantee the agent’s next step unless the architecture does that too.
The next mistake: assuming the signal is enough
This was one of the more important lessons for me.
Once the Scout existed, it was tempting to believe the architecture was now safe. The system checked first. The agent got a hint. That looked disciplined.
But there are really two separate decisions here:
- Does the system check whether prior knowledge exists?
- Does the agent perform the deeper, context-rich retrieval needed for this exact task?
The Scout can enforce the first. It cannot automatically enforce the second.
If I want the second step to happen reliably, I have to design for that explicitly. For example:
- by routing the agent through a mandatory retrieval step,
- by making the deep query part of the execution pipeline,
- by validating whether retrieval actually happened before allowing the workflow to continue,
- or by injecting the retrieved material directly when the task type requires it.
The exact mechanism can vary. The principle does not.
Critical behavior should not depend on whether the agent feels like doing it.
That applies beyond retrieval. Validation. Checkpointing. Outcome capture. Writing experience back. Anything operationally mandatory belongs into the harness.
Even then, the pipeline can still fail silently
This is the part that took me the longest to fully internalize.
A knowledge store is not just a searchable database. It is a pipeline. And a pipeline is only as strong as its weakest link.
The chain looks like this:
Write → Distill → Index → Retrieve → Rank → Present → Act → Learn
Any one of these steps can quietly reduce the value of all the others to zero.
I had a setup that looked correct. The Scout queried. The store contained the knowledge. But one wrong configuration value — a scope parameter that differed between Scout and Agent — caused the agent’s deep query to return nothing useful. Everything looked healthy. Logs were clean. No exception. No timeout. No obvious failure.
Just zero value.
That is the dangerous part. “Looks like it works” is not the same as “works”.
And this was not the only failure mode. I ran into several others:
- Over-abstracted distillation: If the distillation step removes the concrete vocabulary, later retrieval misses because the query uses the concrete terms that no longer exist in the indexed representation.
- Bad score thresholds: In one case, an absolute similarity threshold filtered out every useful hit. The system searched correctly and returned nothing — for the wrong reason.
- Wrong layer queried: At one point, the agent used raw episodes instead of validated insights. The answer still sounded plausible. The source layer was wrong.
That is why retrieval architecture cannot be judged by the existence of a search function. It has to be judged end to end.
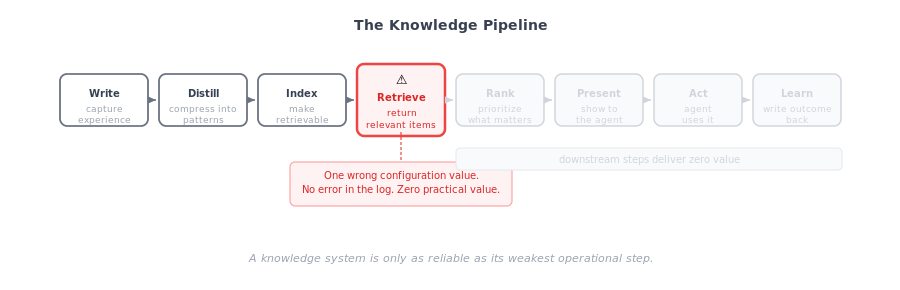
A knowledge system is only as reliable as its weakest operational step.
Four things I would tell someone starting now
These came directly from the failures above. Not theory — what I would have wanted to know at the start.
1. Inject signals. Do not replace judgment.
The knowledge store should expand the agent’s judgment, not replace it. Retrieval can be wrong. Retrieval can be stale. Retrieval can be contradictory. Ensure that relevant prior knowledge becomes visible. But the agent still has to reason about what to do with it.
That is not distrust of AI. That is responsible system design.
2. Graceful degradation is mandatory.
What happens if the knowledge store is unavailable? What happens on timeout? What happens when retrieval returns nothing? The agent continues. Without the additional knowledge, but without collapsing the workflow.
The store is an accelerator. It must not become a brittle single point of failure.
3. Observability comes before optimization.
“Correctly found nothing” and “found nothing because the system is misconfigured” can look identical from the outside. Without logs, metrics, and traceability, a knowledge system becomes a black box. And black boxes are almost impossible to improve.
Before tuning behavior, I need to know what actually happened. Otherwise I optimize the wrong layer.
4. Separate curated knowledge from raw experience.
Validated knowledge and raw experience entries are not the same thing. Different quality. Different trust levels. Different use cases. If an agent queries the wrong layer, the answer can still sound plausible. That is what makes it dangerous.
The separation has to be structural. Not a convention. Not a note in documentation. Architecture.

These principles are architectural, not vendor-specific.
The design principle underneath all of this
If I compress the whole article into one sentence, it is this:
The harness owns the reflexes. The agent owns the reasoning.
Everything non-negotiable belongs into the structure: querying memory, passing checkpoints, validating outputs, capturing outcomes, writing reusable experience back into the system. Everything judgment-heavy stays with the agent: how to interpret the retrieved material, how to weigh conflicting signals, how to solve the actual task.
That is not anti-agent. It is simply disciplined engineering.
In every other software system, I do not leave critical behavior to the goodwill of one component. I enforce it structurally. Agent systems should be designed the same way.
If you are building with a knowledge system like Ogham, that distinction becomes even more important. The value does not come from storing experience alone. It comes from making sure the right experience enters the workflow at the right point, through mechanisms that are reliable even when the agent is not.
That is the difference between a clever demo and a dependable system.
Where in your current architecture does discipline actually live – in the harness, or in hope?