Open Knowledge Format and Ogham: How Knowledge Becomes Truly Usable for LLMs and Agents
Open Knowledge Format promises open, linked knowledge for LLMs and agents. That makes sense – but it only solves part of the problem. In this article, I explain why OKF and Ogham are not opposites, but address two different layers of knowledge – and why good knowledge artifacts alone do not yet create an agent-ready knowledge system.
What is “knowledge” for LLMs and agents, really?
Over the last few days, I came across Google’s proposal around an Open Knowledge Format. My first reaction was not that it contradicts everything I have been thinking about knowledge systems for agents. Quite the opposite.
The more I think about it, the clearer it becomes: Open Knowledge Format and Ogham do not address the same problem. And that is exactly why they do not conflict with each other. They complement each other.
The confusion starts when we put both into the same category.
When we talk about knowledge for agents, many very different things get mixed together: documentation, architecture rules, process descriptions, project notes, decisions, experiences, patterns from earlier projects, and generalized recommendations.
But these are not the same kind of knowledge.
And that distinction matters. As long as we do not separate these things properly, we keep talking past each other. Everything sounds plausible, but the architecture stays blurry.
An API description is not the same as a documented project decision. A lessons-learned note is not the same as a robust pattern that has been validated across multiple cases. And a loosely linked knowledge page is not the same as a system that can give an agent a reliable recommendation in a concrete situation.
That is the core point for me: not all knowledge is the same. And if we want to build agent systems that do more than just read text, we need to take those differences seriously.
What the Open Knowledge Format solves for LLMs and agents
As I understand it, OKF mainly addresses a very real and very obvious problem: knowledge is often stored in forms that are hard for agents and LLMs to use well.
For example, as PDFs, scattered wiki pages, proprietary tool silos, unstructured documents, or files without clear conventions.
An open format that is readable by both humans and models is a sensible step. It makes knowledge more portable, versionable, easier to edit, easier to search, and easier to integrate into existing development and documentation workflows.
In short: OKF makes knowledge artifacts easier to handle.
That is valuable. And I think it is overdue. A large part of what is called knowledge management today is really just storage with poor reusability. Knowledge exists somewhere, but neither humans nor machines can work with it reliably well.
If an open knowledge format helps make content more structured, better linked, and easier to access, that is real progress.
But it is still only part of the problem.
What Ogham as a knowledge system solves – and what it does not
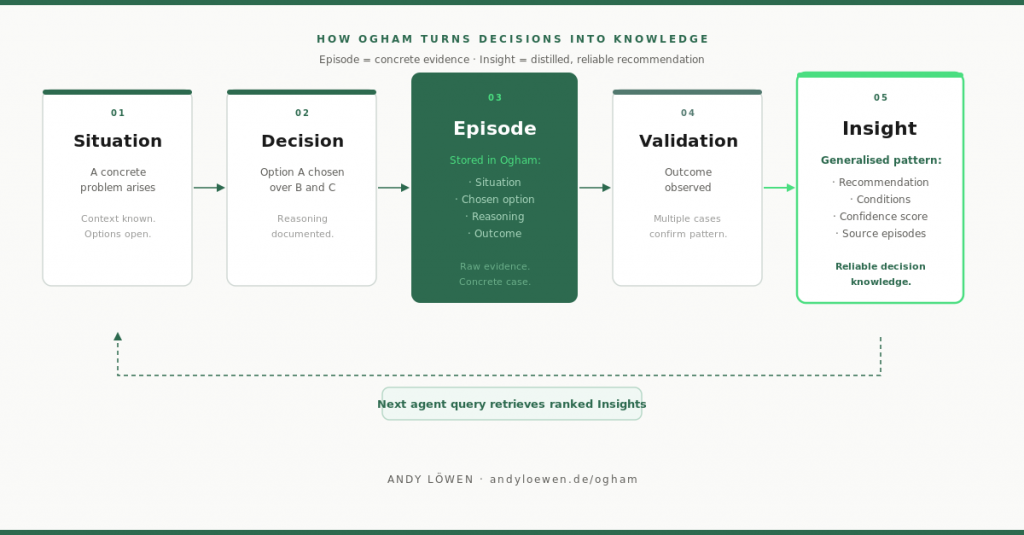
Ogham aims at something different. Not the question of how I store knowledge as a file, but the question of how concrete situations become reliable experiential knowledge.
So not just: here is a knowledge page.
But: in what situation was a decision made? What options existed? Why was option A chosen? What was the outcome? Was the decision successful? Under which conditions does the pattern hold? Which later cases support or contradict that insight?
That is no longer just a documentation problem. It is a learning and decision problem.
That is why I separate Episode and Insight in Ogham. The Episode is the concrete case. The Insight is the generalized recommendation. That distinction is central. And it is exactly what most document models do not represent well.
A document can say: “In projects like this, batch processing should be preferred over streaming.” Ogham should additionally be able to say in which concrete cases that recommendation emerged, which boundary conditions mattered, whether the pattern was later confirmed, and how reliable that statement actually is.
That is a different class of knowledge.
And that is exactly why it would be a mistake to frame OKF and Ogham as competing ideas. They operate on different layers.
Open Knowledge Format vs. Ogham: separating artifact knowledge from experiential knowledge
This is how I would phrase it today: OKF is strong at knowledge artifacts. Ogham is strong at experiential knowledge.
That is not a semantic side note. It is the core distinction.
A knowledge artifact can be an architecture rule, a product description, an API document, a process description, a glossary, or a capability description.
An experiential knowledge entry is something else: in situation X, we chose A over B, for reason Y, under conditions Z, with observed outcome. Later, that became a reusable pattern.
Both are knowledge. But they are not the same class of knowledge.
And that is why it is not enough to dump everything into Markdown files and hope an LLM will understand the difference. That is the same mistake I see in many places right now: better readability gets confused with better knowledge representation.
A well-formatted document is not yet reliable decision knowledge. It is, first of all, just a more accessible document.
Why files alone are not enough for agent-ready knowledge
In earlier discussions, we already touched on the point that “files as knowledge” often falls short. Today I would phrase it more precisely: files are good carriers of knowledge. They are not a good primary form for reliable experiential knowledge.
Why? Because a file alone usually does not model situation, decision, alternatives, rationale, outcome, quality, generalization, and provenance to similar cases in a clean way.
Of course, all of that can be written in Markdown. But just because something is written in a file does not mean it is modeled as a knowledge system.
This is the same mistake that shows up in many RAG approaches: more documents, better chunking, semantic search – and then the hope that the model will extract the right thing.
That often works reasonably well for reference knowledge. For reliable decision knowledge, it is too weak.
And that is where I see the real boundary. Documents are excellent when the goal is to describe knowledge. They are much weaker when the goal is to operationalize knowledge as a reliable basis for decisions.
For that, text alone is not enough. You need structure, context, evaluation, and a connection back to observed outcomes.
Why Open Knowledge Format and Ogham complement each other
Once you separate the layers properly, the picture becomes much simpler.
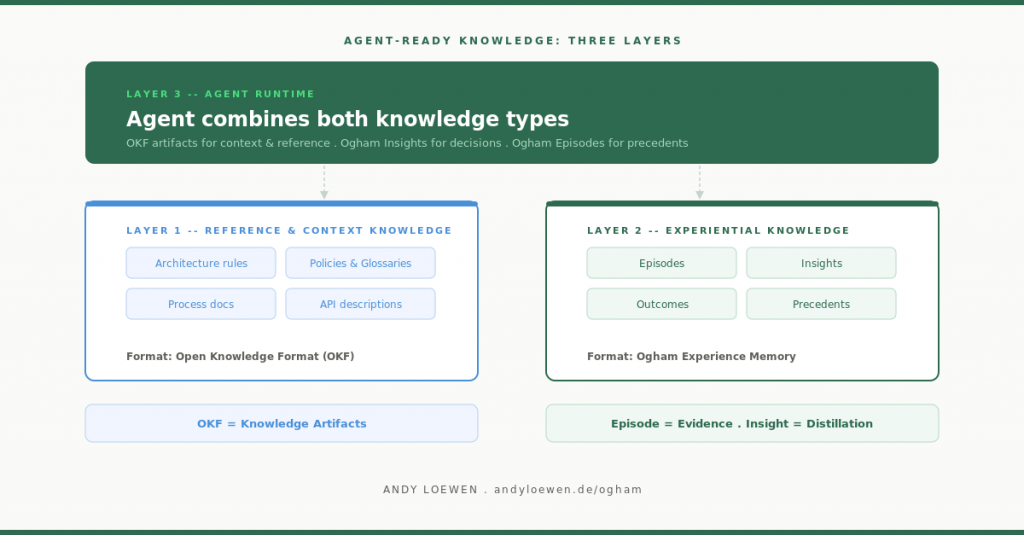
The first layer is reference and context knowledge. OKF fits very well here. For example, for architecture principles, policies, glossaries, tool descriptions, process knowledge, project documentation, or agent handbooks. An open, readable, standardized format makes sense here.
The second layer is episodic experiential knowledge. That is where Ogham fits. For example, for concrete decisions, rationales, observed outcomes, recurring patterns, and reliable recommendations. A document format alone is not enough here.
The third layer is agent runtime usage. This is where it gets interesting. An agent can combine both: OKF artifacts for context and reference, Ogham Insights for recommendations, and Ogham Episodes for concrete precedents.
That is exactly where both approaches complement each other.
To me, this is the cleanest way to frame it. Not either documents or structured knowledge objects, but different knowledge forms for different purposes.
For agents, it is not just about the knowledge format – it is also about access
This is where the discussion becomes practical. One point often remains underexplored: how do agents actually access this knowledge?
A format does not answer that automatically.
If knowledge exists as OKF files, those files still need to be reachable somewhere. Typical options would be a Git repository, a file system, object storage, an API, a CLI, or an MCP server.
That means OKF does not automatically define the access path. It describes how knowledge is structured, not how an agent gets it at runtime.
That matters because too much is often left implicit at exactly this point. The assumption becomes something like: “Once the knowledge is open and well structured, agents can work with it.”
Maybe. But not automatically.
Between “stored in a structured way” and “used correctly at the right time” there is an entire layer of system design.
What agents additionally need to use knowledge well
Even if the files are well structured, the problem is still not solved. An agent still needs to know where to search, find relevant artifacts, decide which ones matter right now, read the content, understand the structure, ignore irrelevant material, and compress all of that into a limited context window.
If that is not solved properly, the files may be openly available, but the agent still works inefficiently. Then you only have better formatted documents. Not yet a good knowledge system.
And this is where a knowledge question turns into a runtime question.
An agent does not work like a human calmly browsing through a wiki. It works under context limits, cost constraints, uncertainty, and often time pressure. That means it does not just need access to knowledge. It needs help finding relevant knowledge precisely and excluding irrelevant knowledge aggressively.
If that layer is missing, you quickly end up with a system that theoretically knows everything, but in practice reads the wrong thing or fails to find the right thing in time.
Linking is not the same as navigation
In the Google context, OKF is also framed as a kind of LLM wiki – a linked knowledge base. As a way of organizing knowledge, that makes sense. Links help with navigation, context building, semantic structure, and human orientation.
But this is also where a common misconception appears.
Just because documents are linked does not mean an LLM or agent will follow those links in a useful way. A link is only a possible path. Nothing more.
The real question is: who decides at runtime which links should be followed, according to which rules, with which budget, and to what depth?
If there is no clear answer to that, then an LLM wiki is, at first, just well-structured hope.
And that is the mistake as I see it: if you believe agents will automatically follow linked documents in a sensible way, you are replacing system design with hope.
This is one of the most important points in the whole discussion for me. Linking creates structure. But linking does not create discipline.
A human can often decide quite well which link to follow in a wiki and which one to ignore. An agent needs rules, heuristics, priorities, or tools for that. Otherwise the behavior remains opportunistic.
Is the intelligence then in the LLM alone?
Partly. But that is exactly what I would not rely on.
If an agent simply gets access to a pile of files and is expected to search, read, and interpret them on its own, that may be flexible, but it is also error-prone. Then too much depends on how good the search is, how good the file structure is, how consistent the metadata is, how precise the linking is, how well the model recognizes relevance, and how much context fits into the window at all.
That is possible. But it is not robust enough when reliable decisions matter.
To me, this is the same design mistake that often appears in agent systems more broadly: the system is given freedom, and then sensible behavior is simply assumed to emerge from that freedom.
People hope for intelligence where they actually need mechanism.
And that is why I do not think it is enough to store knowledge in an open and linked way. You also need to define how that knowledge is supposed to be used.
Why Open Knowledge Format needs additional retrieval support in practice
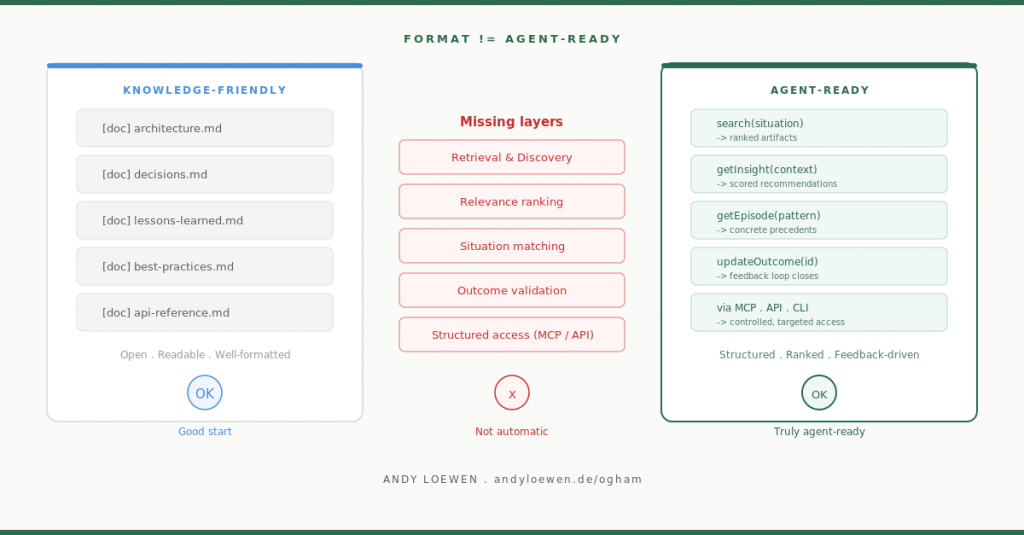
If OKF is meant to become truly agent-ready, it needs more than files. For example: clear metadata, stable identifiers, semantic or structural search, links between artifacts, tables of contents or indexes, defined access points, retrieval logic, and possibly specialized tools that do not just return files, but return the relevant excerpts.
In other words: the format is only the lowest layer. Above that, you need an access layer. And above that, you often need an interpretation layer.
This is where many discussions stop too early. People talk about file formats, Markdown, openness, and interoperability. All of that is valid. But actual agent-readiness only emerges when a system can not only store knowledge, but also provide it in a controlled way.
A good knowledge format is necessary. But it is not sufficient.
How agents can access OKF knowledge: MCP, API, or CLI
From an agent perspective, several access paths are possible.
Direct file access is simple, but often too raw. API access is more controlled and usually better for production systems. CLI tools can work well in developer environments. In this context, I find MCP especially interesting because it standardizes access for agents more explicitly.
Then the agent does not blindly inspect files. Instead, it uses targeted tools such as: search relevant knowledge artifacts, load artifact X, retrieve metadata, follow references, or return only the relevant section.
That is much stronger than saying: here is a folder full of Markdown files, good luck.
The difference is not cosmetic. It is architectural.
With good tool-based access, not only is knowledge provided, but behavior is also guided. The agent does not simply get everything. It gets what is useful for the current step. That reduces noise, saves context, and increases the chance that the system behaves reproducibly.
That is exactly why I consider MCP or similar access layers so relevant. Not because files do not matter, but because files alone do not create good runtime integration.
Why Open Knowledge Format needs a retrieval layer
If OKF is meant to matter in practice, it will almost certainly not stop at being a file format. It will need an additional layer for discovery, retrieval, navigation, and context preparation.
Otherwise it remains a well-intentioned storage format.
And that is where I see the boundary between knowledge-friendly and agent-ready.
Knowledge-friendly means content is open, readable, structured, and maintainable.
Agent-ready means a system can find relevant knowledge precisely, prioritize it, constrain it, and make it reliably usable in a concrete situation.
Those are not the same thing.
And I think this distinction will become more important over the coming months. The more organizations start preparing knowledge for agents, the more obvious it will become that good documents alone do not create good agent systems.
How Open Knowledge Format and Ogham can be combined architecturally
If I had to reduce it to an architectural principle, I would phrase it like this: OKF for declarative knowledge material. Ogham for episodic and distilled experiential knowledge.
Or even shorter:
- OKF = Knowledge Artifacts
- Ogham Episode = Knowledge Evidence
- Ogham Insight = Knowledge Distillation
To me, that is the cleanest separation.
Then Ogham does not need to replace OKF. And OKF does not need to imitate Ogham. Both have a clear role.
I actually think this division of labor is more productive than trying to force everything into one single knowledge model. That is usually where things become messy. Then one document is supposed to be reference, decision, experience, recommendation, and runtime context all at once. That sounds elegant, but in practice it usually just mixes different requirements together.
It is cleaner to keep the roles distinct.
What this means for agent systems and knowledge management
A good agent system should not just be able to read documents. It should distinguish between reference knowledge, context knowledge, decision knowledge, and experiential knowledge.
And it should treat those knowledge types differently.
An architecture rule is used differently from a precedent. A product description is used differently from a validated Insight. A process description is not the same as a recommendation distilled from multiple projects.
If everything is thrown into the same retrieval bucket, those differences disappear. That is convenient. But it is conceptually sloppy.
And that is exactly why I find the combination of open knowledge artifacts and structured experiential knowledge so compelling. It allows knowledge not only to be stored better, but also to be used more intelligently.
To me, that is the real maturity step: not just more knowledge, but better modeled knowledge for different purposes.
Conclusion
I do not see Open Knowledge Format as a counter-model to Ogham. I see it as a useful complement on a different layer.
OKF helps provide knowledge as an open, readable artifact. Ogham helps turn concrete decisions into reliable experiential knowledge.
One does not replace the other. But together they can form a much stronger knowledge system: open knowledge artifacts for context, structured Episodes for evidence, and distilled Insights for better decisions.
So for me, the real open question is not only the format. The more interesting question is this: how do agents get controlled, targeted, and reliable access to that knowledge?
Because that is where it is decided whether open files actually become agent-ready knowledge.
Maybe that is the right dividing line: not every kind of knowledge should be modeled as a file. But good knowledge management for agents still needs good files.
The real skill is not choosing one or the other. The real skill is creating a clean division of labor.